


Угадывать клиентские предпочтения – дело непростое.
Здесь на помощь Пану Агенту приходит искусственный интеллект. Используя технологии машинного обучения, мы можем сформировать разумные, обоснованные прогнозы продаж.
Они имеют реальную ценность, поскольку являются плодом анализа больших объемов данных и закономерностей в них.
Пан Агент просеивает информацию о продажах, находит паттерны и проецирует эти паттерны на новые заказы.
Представляем новый модуль Динамические рекомендации.
Обычно системы прогнозирования представляют из себя нечто сложное, непонятное и довольно-таки неповоротливое.
Но только не в нашем случае.
Предсказания Пана Агента производятся на лету. В то время, как агент формирует заказ, система в фоновом режиме производит все расчеты и предоставляет пользователю список тех товаров, которые с большой долей вероятности могут быть проданы текущему клиенту, исходя из тех позиций которые он уже заказал.
Рекомендации отображаются непосредственно в заказе. Достаточно выбрать любую рекомендованную позицию – и она будет сразу же перенесена в документ.
В Пане Агенте реализованы две модели предсказаний. Обе они используют методы коллаборативной фильтрации, задача которых формулируется как прогнозирование неизвестных предпочтений одного пользователя на основе известных предпочтений других пользователей.
Первая модель называется Клиент к клиенту. Суть ее в том, что система находит чеки, максимально похожие на текущий, и делает по ним выводы о том, какие недостающие товары из этих похожих чеков можно предложить клиенту.
Вторая модель называется Товар к товару. Ее создателем является компания Amazon, которая давно и успешно использует ее в своей экосистеме. Система ищет комбинации товаров, которые чаще всего встречаются в продажах, и на основе этого делает выводы, какие товары лучше всего продаются вместе с выбранными.

Осторожно.
Много технической информации!
Мне не интересны технические детали. Перейти к заключению.
Рассмотрим подробнее работу обеих моделей прогнозирования.
Сбор и очистка данных о продажах.
Данный этап является общим (и обязательным) для всех моделей предсказаний.
Большинство алгоритмов машинного обучения строят свои модели на основании обучающей выборки данных.
Точность предсказания модели напрямую зависит от качества этих данных.
Например, в алгоритмах машинного зрения достаточно всего лишь 5% “мусора”, чтобы качество распознавания изображений стало неприемлемым.
В нашей задач обучающая выборка строится на основании данных о продажах.
Структура таблицы продаж выглядит так:
| Код чека (код заказа) | Код товара |
Построим график распределения количества товаров в чеках в двух базах данных.
Первая база данных принадлежит розничной сети. Вторая – оптовому дистрибьютору. Определим закономерности для каждой из них.
| База данных розничной сети | База данных оптового дистрибьютора |
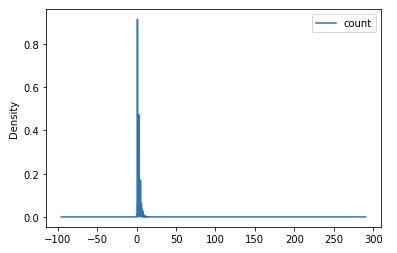 | 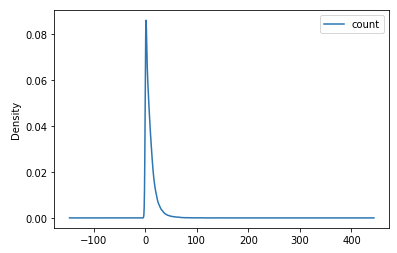 |
Из графика видно, что среднее количество позиций в чеке оптового дистрибьютора выше, чем у розничной сети. Но и там, и там с максимальной частотой встречаются чеки с относительно небольшим количеством товаров.
Ограничим выборку чеками, содержащими до 50 товаров.
Кроме того, уберем из выборки чеки, содержащие только один товар. Такие чеки не несут никакой информации о том, какие товары покупались совместно.
Еще раз построим графики.
| База данных розничной сети | База данных оптового дистрибьютора |
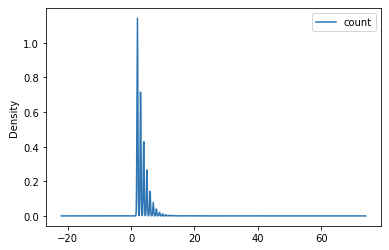 |  |
Посмотрим на то же распределение уже в табличном виде.

Из таблиц видно, что чем больше количество товаров в чеке, тем реже такой чек встречается. Примем за верхнюю границу значимого диапазона 30 товаров.
Таким образом, мы очистили данные от мусора (чеки с одним товаром) и убрали малозначимые данные (чеки > 30 товаров).
Модель Клиент к клиенту (Customer to customer).
Суть данного алгоритма очень проста: когда покупатель выбирает товары в чек, то нам необходимо найти чеки с максимально похожим составом товаров.
После чего предложить покупателю те товары из похожих чеков, которые он еще не купил.
Представим все чеки в виде таблицы:
| Товар 1 | Товар 2 | Товар 3 | … | Товар N | |
| Чек 1 | 1 | 0 | 0 | … | 1 |
| Чек 2 | 1 | 1 | 1 | … | 0 |
| … | … | … | … | … | … |
| Чек N | 0 | 1 | 1 | … | 0 |
- По вертикали – чеки.
- По горизонтали – весь ассортимент товаров.
- На пересечении – 1, если данный товар был куплен в этом чеке; 0 – если не был.
Текущий чек, или заказ, мы представляем в виде такой же таблицы, с одной строкой.
| Текущий чек | 1 | 0 | 1 | … | 0 |
Поиск похожих чеков (просто и медленно).
Необходимо пройтись по всей таблице и для каждого чека посчитать сколько товаров совпало с текущим чеком покупателя.
Чеки, в которых совпало максимальное количество товаров с текущим чеком, считаются максимально похожими на текущий чек.
Все бы хорошо, но на больших данных этот алгоритм будет отрабатывать не очень-то и шустро. Нас это не устраивает.
Поиск похожих чеков (сложно и быстро).
Чтобы добиться максимальной скорости расчета, необходимо представить чеки в векторном виде. Каждый чек, вместо строки таблицы, представлен многомерным вектором:
Чек 1 = (1; 0; 0; …; 1), Чек 2 = (1; 1; 1; …; 0), …, Чек N = (0; 1; 1; …; 0)
Текущий чек = (1; 0; 1; …; 0)
Для поиска похожих товаров необходимо найти максимальный косинус угла между векторами.

Рассмотрим на примере.
Для простоты представления допустим, что у нас в системе всего лишь 3 товара и 3 чека в истории продаж.
Тогда:
Чек 1 = (1; 0; 0)
Чек 2 = (1; 1; 1)
Чек 3 = (0; 1; 1)
Текущий чек = (1; 0; 1)
Получаем трехмерную систему координат (по числу товаров).
Отобразим данные чеков графически в системе координат:
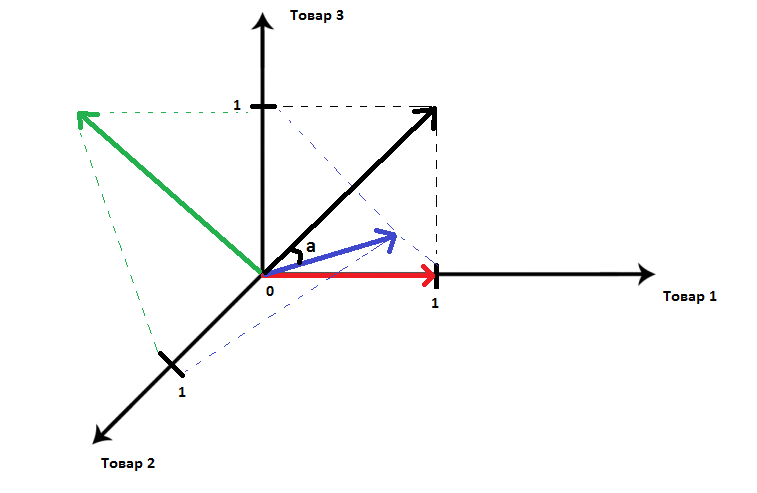
Как видно на графике, минимальный угол и, следовательно, максимальный косинус находится между текущим чеком и чеком №2.
Для поиска минимального угла между векторами, представим все чеки в виде матриц: А — матрица прошлых продаж, В — текущий чек.
1 0 0
А = 1 1 1 ; В = 1 0 1
0 1 1
1
cos = A * B’ = 2
1
B’ — транспонированная матрица В.
Видно, что максимальный косинус оказался между текущим чеком и чеком № 2.
Обработка полученной информации.
Все пересекающиеся товары в текущем чеке и похожих чеках убираем. Если в чеке не осталось ни одного товара, то его не рассматриваем: такой чек не несет дополнительной информации о позициях, которые можно допродать.
Оставшиеся чеки выстраиваем в порядке количества совпавших товаров (по убыванию) и количества оставшихся товаров (по возрастанию).
Таким образом, самыми верхними чеками, окажутся те, в которых совпало максимальное количество товаров с текущим чеком и этот чек отличается от текущего на минимальное число товаров.
Идем по таблице оставшихся чеков, смотрим, какие товары в них остались после исключения товаров, уже имеющихся в текущем чеке, и для каждого товара подсчитываем сколько раз он покупался.
Достаточно посмотреть первые 100 чеков, чтобы набрать статистику по максимально покупаемым товарам в похожих чеках.
Преимуществом этой модели является то, что мы оцениваем чеки целиком, и отслеживаем паттерны поведения покупателей, выявляя устоявшиеся продуктовые корзины.
Модель Товар к товару (Item to Item).
Данная модель был предложена компанией Amazon. Компания столкнулась с тем, что, с учетом огромных объемов продаж компании и многообразия ее клиентов, рекомендации по алгоритму Customer to customer формировались непозволительно долго.
Компания решила отталкиваться не от общей похожести чеков, а от количества вхождений различных комбинаций товаров в разные чеки, вне зависимости от покупателя.
Для начала, построим таблицу товаров, когда-либо продававшихся вместе, в одном чеке, по всей истории продаж, без учета конкретных покупателей.
Таблица совместных продаж выглядит, примерно так:

Колонка Count содержит кол-во чеков, в которых товары встречались вместе. Если товары вместе никогда не продавались, то их комбинация в таблицу не попадает.
Условимся, что если товары вместе встречались меньше 100 раз, то эти совпадения, скорее являются случайностью, нежели чем закономерностью.
И потому все строки, где число совпадений меньше 100 удалим.
По таблице совместных продаж, сформируем матрицу совместных продаж:
| 000000559 | 000000561 | 000000562 | 000000566 | 000000686 | 000002120 | 000003084 | … | |
| 000000559 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | … |
| 000000561 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | … |
| 000000562 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | … |
| 000000566 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | … |
| 000000686 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | … |
| 000002120 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | … |
| 000003084 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | … |
| … | … | … | … | … | … | … | … | … |
Если товар продавался более чем 100 раз вместе с другим товарам, то на пересечении этих товаров ставится 1. Если не продавался, то 0.
Затем оценим, насколько товары совместимы между собой, т.е. с большой вероятностью встречаются в чеках вместе.
Для этого воспользуемся тем же алгоритмом поиска похожих векторов, как и при поиске ближайших покупателей. Будем искать максимальный косинус угла между векторами.
Обозначим всю нашу матрицу совместных продаж буквой А.
В цикле пройдем по строкам матрицы и формируем единичный вектор В из каждой строки матрицы.
Для каждого вектора В выполняем умножение А*В’ . Получим коэффициенты совместимости товара из текущей строки матрицы на все товары. Запоминаем для каждого товара 100 товаров с самыми большими коэффициентами совместимости.
Обработка полученной информации.
При выборе товаров покупателем:
- Для каждого выбранного товара получаем совместимые товары.
- Отбрасываем те товары, что уже есть в чеке.
- Группируем похожие товары, суммируя коэффициент совместимости.
- Выстраиваем список совместимых товаров в порядке убывания суммы коэффициента совместимости.
- Рекомендуем покупателю первые N товаров из списка.
Преимущество алгоритма состоит в том, что мы заранее просчитываем совместимость товаров. Нет необходимости все считать онлайн, соответственно скорость работы, особенно на больших базах, будет выше.
Заключение.
Обе модели, используемые Паном Агентом, позволяют мгновенно генерировать рекомендации по продажам, реагируя на изменения в заказе или в чеке.
Эффективные алгоритмы обработки больших данных обеспечивают предоставление покупателю максимально адекватного и обоснованного торгового предложения. Такие, подтвержденные жизнью и большими данными рекомендации, обеспечивают рост дополнительных продаж.
Динамические рекомендации доступны в стандартной поставке приложения Пан Агент.
В настоящее время модуль Динамических рекомендаций опубликован в бета-версии системы.

 +7 (4012) 76-55-00,
8 (800) 700-68-75
+7 (4012) 76-55-00,
8 (800) 700-68-75


